Behavioral analysis has become one of the most important new ideas in the movement ecology literature. Due to the importance of the internal state in individual movement decisions, analyses such as the ones we will go through today offer an opportunity to understand the motivations underlying space-use more clearly than most of the broader scale analyses we’ve seen thus far. We are going to begin by considering Hidden Markov Models (HMM) as a means of exploring the behavioral states of our focal animals. Then, we will explore some methods in behavioral change point analysis (BCPA), before ending with a quick survey of some other novel methods in this space.
Hidden Markov Models (HMM)
We will begin by loading in a dataset that comes with the moveHMM package, an elk movement track that is analyzed in the Morales et al. 2004 that introduces many of the concepts with which we will be working.
library(moveHMM)
## Loading required package: CircStats
## Loading required package: MASS
## Loading required package: boot
head(elk_data)
## ID Easting Northing dist_water
## 1 elk-115 769928 4992847 200.00
## 2 elk-115 766875 4997444 600.52
## 3 elk-115 765949 4998516 561.81
## 4 elk-115 765938 4998276 550.00
## 5 elk-115 766275 4998005 302.08
## 6 elk-115 766368 4998051 213.60
We can see that the data consists of four columns: an ID row (we actually have 4 different elk), and Easting and Northing coordinate, and an auxillary variable of dist_water. Whenever we see “Easting” and “Northing” as opposed to “Longitude” and “Latitude”, we know that the coordinates are in UTM (meaning that the units are in meters). For the sake of this analysis, we are actually going to transform these into kilometers, which represents a more reasonable scale when considering steps of this magnitude. Simply dividing each coordinate column by 1000 will do just that:
elk_data$Easting <- elk_data$Easting/1000
elk_data$Northing <- elk_data$Northing/1000
Notice that this data set is missing the time stamps of these steps. We actually have no idea what the fix rate is for this dataset, meaning that analyses built around a temporal component (like T-LoCoH or Brownian Bridges) could not be performed on these data.
Fortuantely, the spatial data are perfectly usable for a hidden Markov model analysis. Now that we have the correct units (km), we can move on to prepping the data for the moveHMM package. This requires the use of the moveHMM::prepData command. We will specify our data, the type of projection (in our case ‘UTM’, though if our data were latlong coordinates, we could use ‘LL’), and the names of the columns representing our coordinates (Easting and Northing):
data <- prepData(elk_data, type="UTM", coordNames=c("Easting","Northing"))
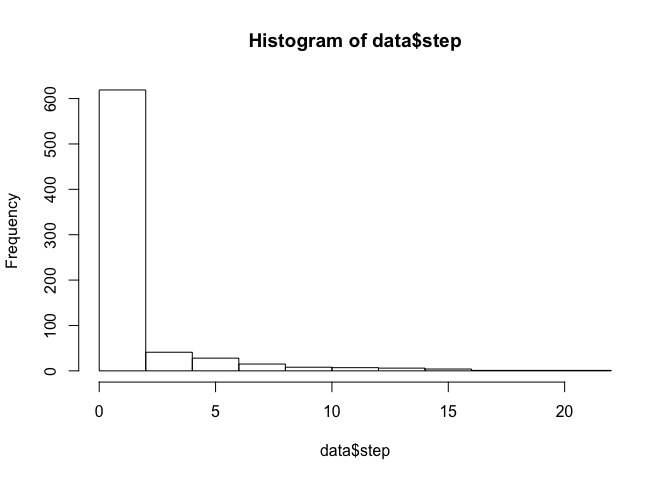
Now we have an object (data) with 6 variables instead of 4. The two new variables are ‘step’ (step length, calculated in km) and ‘angle’ (in radians; i.e., ranging from -pi to pi). Let’s take a look at the distributions of these two new variables:
hist(data$step)
hist(data$angle)
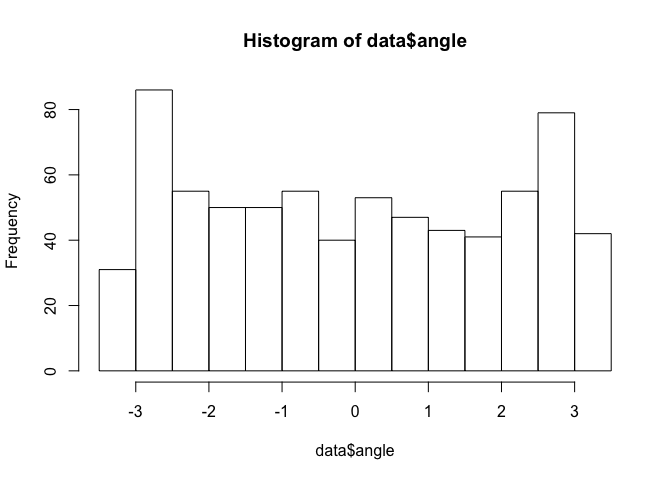
Note that these histograms include all four elk. We can also take a look at a summary of our newly created dataset to see the number of observations associated with each elk as well as a distbution of our covariate (distance to water):
summary(data)
## Movement data for 4 tracks:
## elk-115 -- 194 observations
## elk-163 -- 159 observations
## elk-287 -- 164 observations
## elk-363 -- 218 observations
##
## Covariate(s):
## dist_water
## Min. 25% Median Mean 75% Max.
## 0.0000 213.6000 477.6200 773.6457 1169.4950 3781.0400
We can also visualize the paths using the plot command. This will give us the path itself and time series plots of the step length and turning angle. This is a good way to check for outliers in the data:
plot(data[data$ID == "elk-115",])
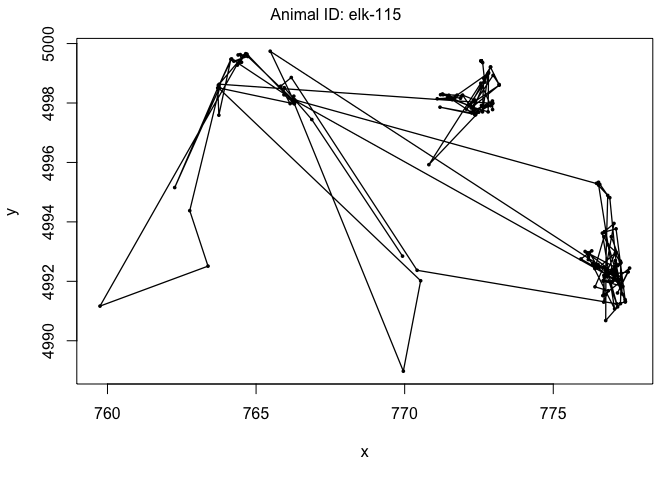
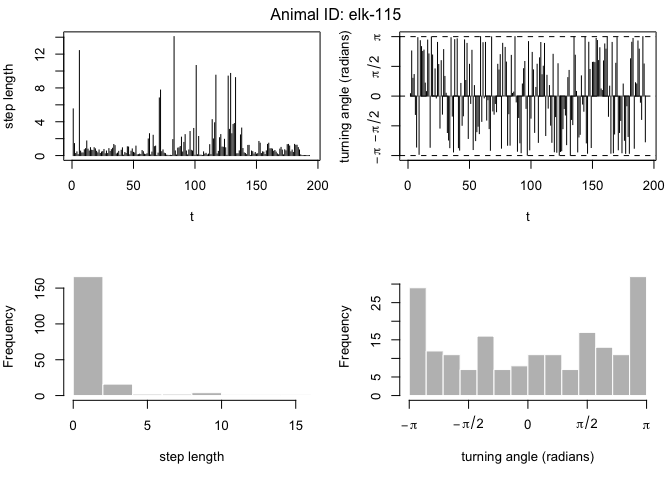
Now it is time to fit an HMM to the data. To do this, we will use the moveHMM::fitHMM command. This is a pretty complex function, however, that requires quite a few inputs to make it run smoothly. Ultimately, our goal is to build a two-state model that relates the behavioral state to the distance from water covariate.
Our first choice will be to use nbStates=2 which specifies that we want to fit a two-state model to the data. Then we will offer a formula to guide the calculation of the function regarding transitions between states (formula=~dist_water). Next we want to define the distrbutions that we want to use to characterize both the step lengths and turning angles. We are going to use a gamma distribution for the former (stepDist="gamma") and a vonMises distribution for the latter (angleDist="vm"). That takes care of that, but we’re still not ready to run our function just yet. We want to define some initial values for the state-dependent functions so that the optimization algorithm has a starting point. In this case, the initial parameters should be specified in two vectors, stepPar0 (for the step distribution) and anglePar0 (for the angle distribution). The exact parameters for each can be found in the documentation, but for a gamma distribution, we will need a mean, SD, and zero-mass and for the vonMises, we will need a mean and concentration parameter:
mu0 <- c(0.1,1) # step mean (two parameters: one for each state)
sigma0 <- c(0.1,1) # step SD
zeromass0 <- c(0.1,0.05) # step zero-mass
stepPar0 <- c(mu0,sigma0,zeromass0)
angleMean0 <- c(pi,0) # angle mean
kappa0 <- c(1,1) # angle concentration
anglePar0 <- c(angleMean0,kappa0)
The final bit of preparation is to standardize our covariate (i.e., subtract the mean and divide by the standard deviation):
data$dist_water <- (data$dist_water - mean(data$dist_water)) / sd(data$dist_water)
Finally, we can put all of these things together in our moveHMM::fitHMM command:
m <- fitHMM(data=data, nbStates=2, stepPar0=stepPar0, anglePar0=anglePar0, formula=~dist_water)
Fortunately, that doesn’t take too longe even though there are some pretty intense calcualtions going on in the background. This is primarily because we are fitting relatively few data points (only 735 in total). We can take a look at the resulting model m:
m
## Value of the maximum log-likelihood: -1887.446
##
## Step length parameters:
## ----------------------
## state 1 state 2
## mean 0.352469507 3.332988e+00
## sd 0.374852722 4.310057e+00
## zero-mass 0.001990027 9.216169e-08
##
## Turning angle parameters:
## ------------------------
## state 1 state 2
## mean -2.9941909 0.1332321
## concentration 0.6011662 0.2224446
##
## Regression coeffs for the transition probabilities:
## --------------------------------------------------
## 1 -> 2 2 -> 1
## intercept -2.0385282 -0.706258
## dist_water -0.3657492 1.059078
##
## Initial distribution:
## --------------------
## [1] 0.3115742 0.6884258
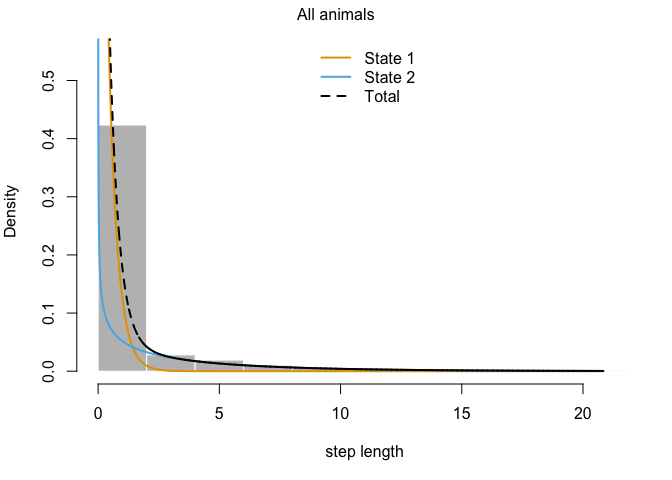
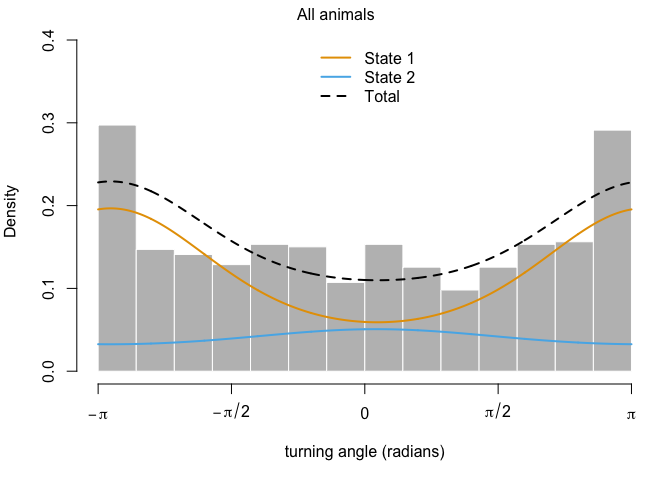
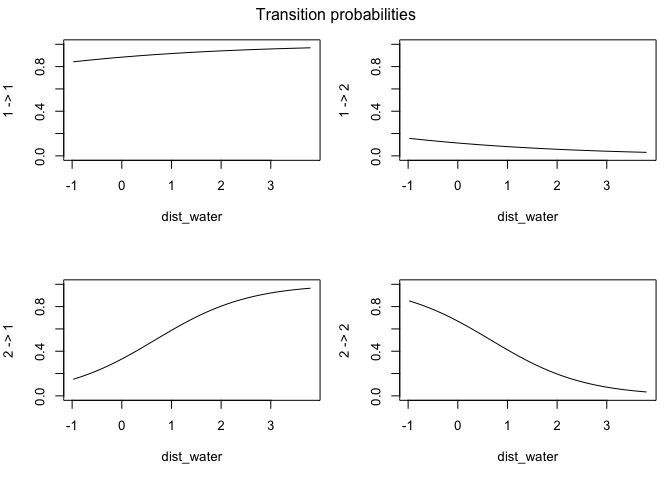
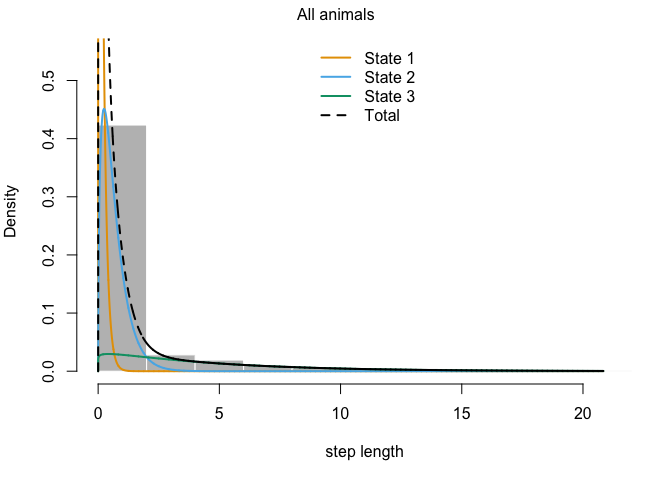
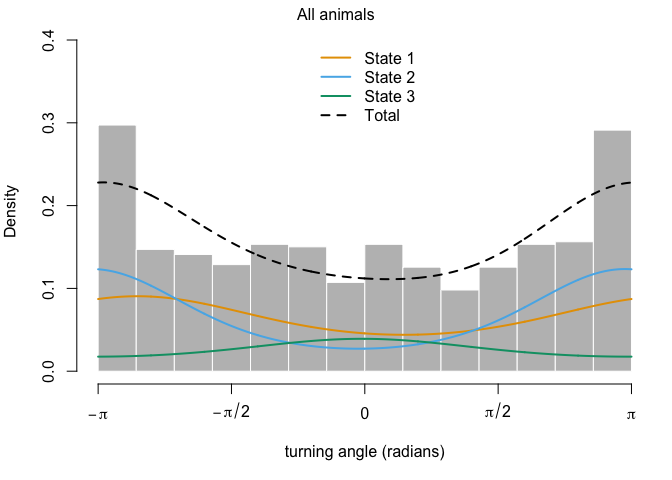
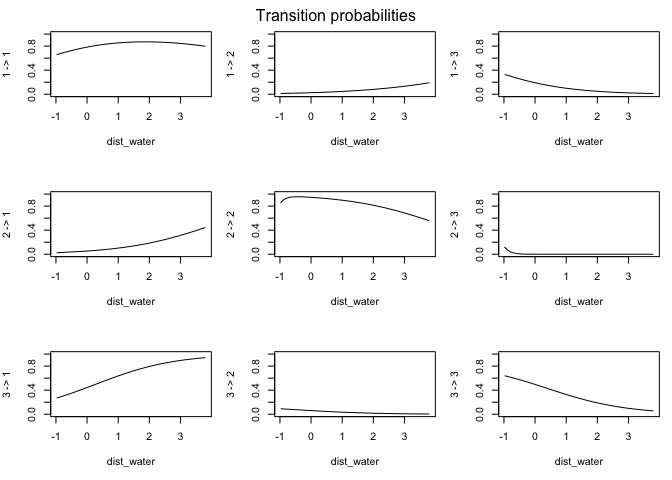
This output has all sorts of interesting information for us. The first thing we can see is a log-likelihood value. Good to know, but not especially meaningful by itself. Next, we have the step length parameters. The model has explored parameter space for the mean, SD, and zero-mass parameters and returned optimal values of each for both of our (as-yet-unnamed) behavioral states. We can see right off the bat that the mean step size of state 1 is an order of magnitude smaller than that of state 2, so we have some idea about what kind of activities may be occuring in each. We may have something like foraging during state 1 and more directional movement during state 2. The next section defines the turning angle parameter estimates. Next, we can see the regression coefficients for the simple formula we set up to calculate state transition probabilities based on the distance from water. This suggests that an increase in distance from water makes it more likely that an animal that it in state 2 (i.e., moving relatively long distances) will switch to state 1. Conversely, greater distance from water are unlikley to shift an individual from state 1 to state 2.
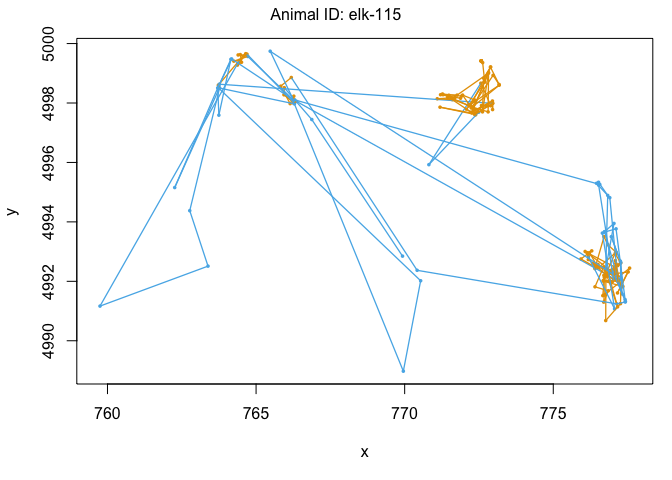
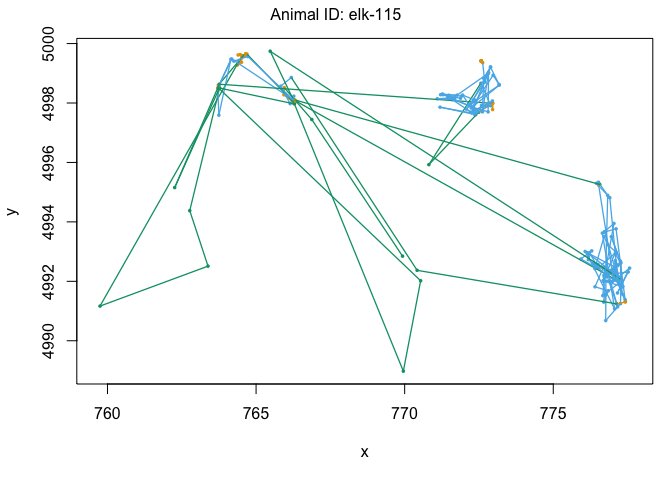
We can also use the moveHMM::plot command to visualize all of these things, beginning with the distributions of step lengths and turning angles in the two states, illustrating the transition proababilities between states, and then showing each of the four paths with each point assigned to the most likely state.
plot(m)
## Decoding states sequence... DONE
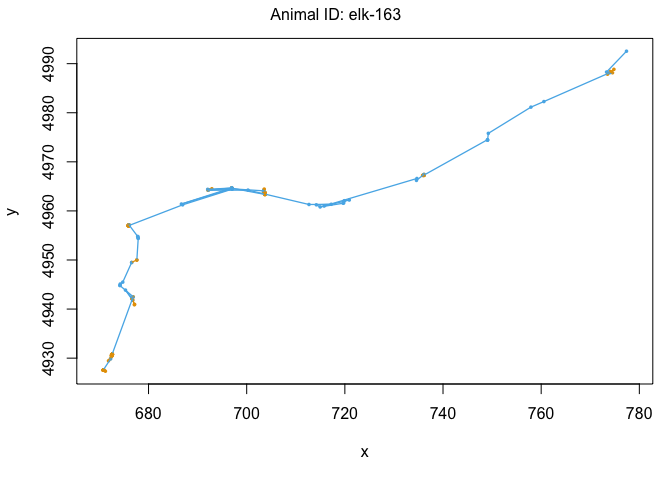
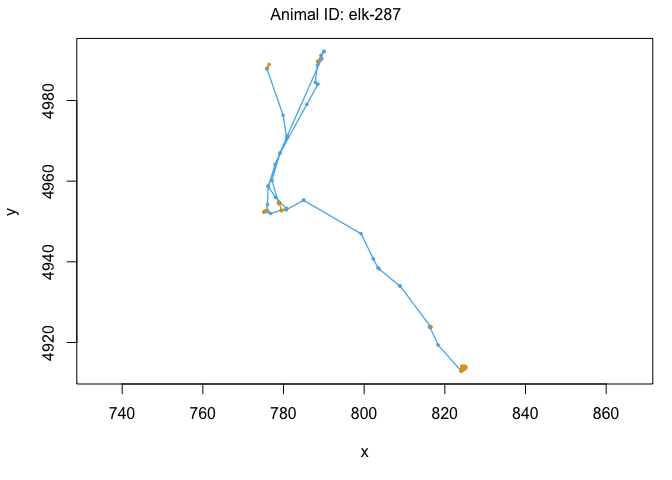
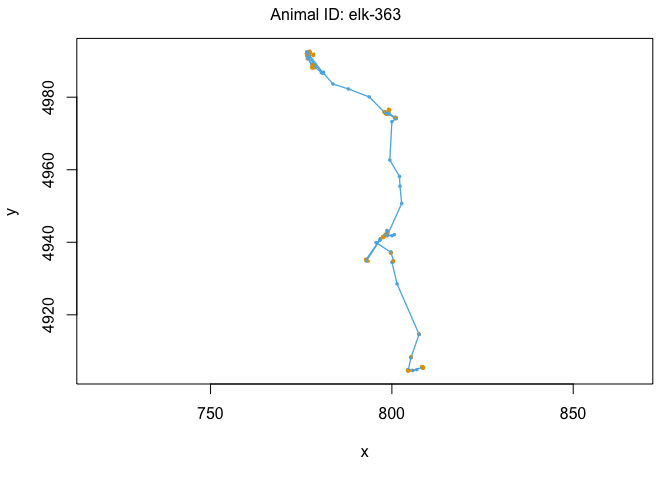
We’ve officially built our first hidden Markov model! That was pretty exciting. Let’s see some ways that we can use the model outputs. The first is to ‘decode’ the behavioral states along the paths. This was done for us when we plotted each track above, but if we wanted to see the most likley states for each point, we could use the moveHMM::viterbi command, which uses the Viterbi algorithm to predict the most likely sequence of states that generated these paths:
states <- viterbi(m)
states
## [1] 2 2 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [36] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2
## [71] 2 2 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 1 1
## [106] 1 1 1 1 1 1 1 1 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 2 2 1 1
## [141] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [176] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 2 2 2 2 2 2 2 1 1
## [211] 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 2 1 1 1 2 2 2 2 2 2 2 2 2 1
## [246] 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [281] 1 1 1 2 2 2 2 2 1 1 1 2 2 2 2 2 1 1 1 1 1 1 1 1 2 2 1 1 2 1 1 1 1 1 1
## [316] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1
## [351] 1 1 1 1 1 1 1 2 2 2 2 2 2 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2
## [386] 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1
## [421] 1 1 1 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1
## [456] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [491] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [526] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
## [561] 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1
## [596] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 2 2 2 2 1 1
## [631] 1 1 1 2 2 2 2 2 2 1 1 1 1 1 1 1 1 2 2 2 2 2 1 1 1 1 1 1 1 1 2 1 1 1 1
## [666] 1 1 1 2 2 2 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 2 2 1 1 1 1 2 1 1 1 1 1 1 2
## [701] 1 2 2 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Thats pretty neat! From this, we can determine the proportion of time that elk spent in one state versus the other:
prop.table(table(states))
## states
## 1 2
## 0.7414966 0.2585034
It turns out these animals were in the foraging state nearly three times as frequently as they were in the directional movement state.
If we wanted to get a little bit more information of the probabilities of each animal being in a particular state at a given time, we could use the moveHMM::stateProbs command on our model. In this case, rather than extracting one most likely state for each point, the actual probabilities of both states are displayed for each point. The state with highest probability according to stateProbs might not be the same as the state in the most probable sequence returned by the Viterbi algorithm. This is because the Viterbi algorithm performs ‘global decoding’, whereas the state probabilities are ‘local decoding’
state.probs <- stateProbs(m)
head(state.probs)
## [,1] [,2]
## [1,] 7.909565e-06 0.9999921
## [2,] 1.016963e-01 0.8983037
## [3,] 6.380862e-01 0.3619138
## [4,] 6.005523e-01 0.3994477
## [5,] 4.553708e-01 0.5446292
## [6,] 2.397904e-11 1.0000000
We can also visualize these probabiities using moveHMM::plotStates, and can specify whether we want to view a specific animal:
plotStates(m, animals="elk-115")
## Decoding states sequence... DONE
## Computing states probabilities... DONE
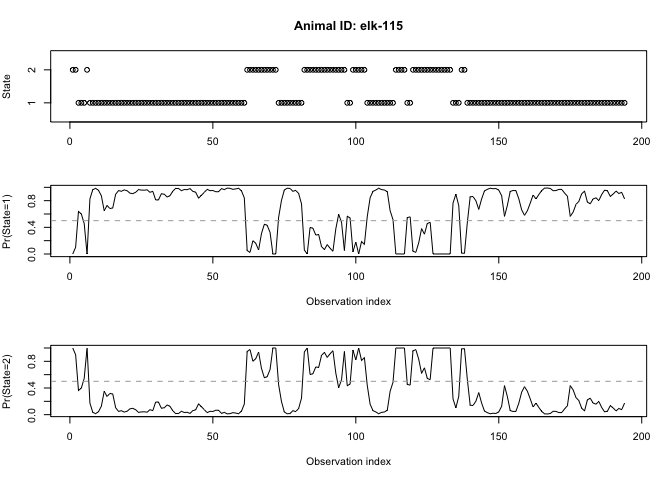
Now you may be wondering why we chose a two-state model rather than a three- or four-state model. Well, there was no great reason, so let’s evaluate whether this was a decent decision for us to have made and determine whether we want to move forward with this particular HMM.
Here, we’ll carry out the same procedure, but initialize and fit a three-state model. Then, we can use the moveHMM::AIC command to compare the likelihood values (or more accurately, the information criterion values derived from the liklihoods) and determine which model performed better.
# initial parameters
mu0 <- c(0.1,0.5,3)
sigma0 <- c(0.05,0.5,1)
zeromass0 <- c(0.05,0.0001,0.0001)
stepPar3 <- c(mu0,sigma0,zeromass0)
angleMean0 <- c(pi,pi,0)
kappa0 <- c(1,1,1)
anglePar3 <- c(angleMean0,kappa0)
m3 <- fitHMM(data=data, nbStates=3, stepPar0=stepPar3, anglePar0=anglePar3, formula=~dist_water)
AIC(m, m3)
## Model AIC
## 1 m3 3661.988
## 2 m 3804.891
This model took a little longer to run than the two-state model, but it turns out its actually more accurate (lower AIC is better; it indicates that we got additional information that was more beneficial than the additional cost of adding a a few parameters). Now we can take a look at our more accurate model:
plot(m3)
## Decoding states sequence... DONE
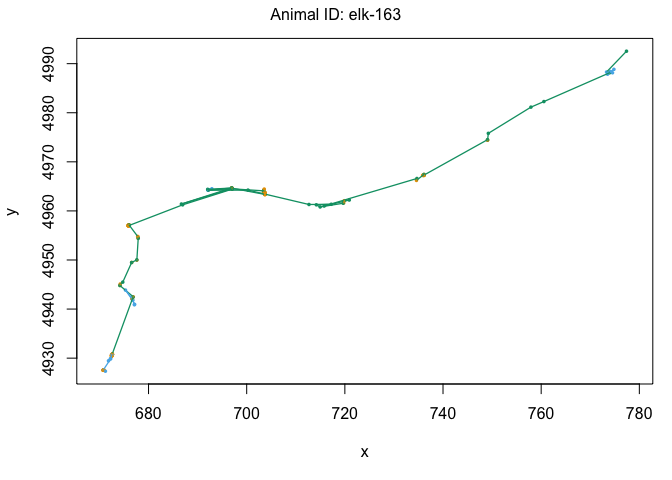
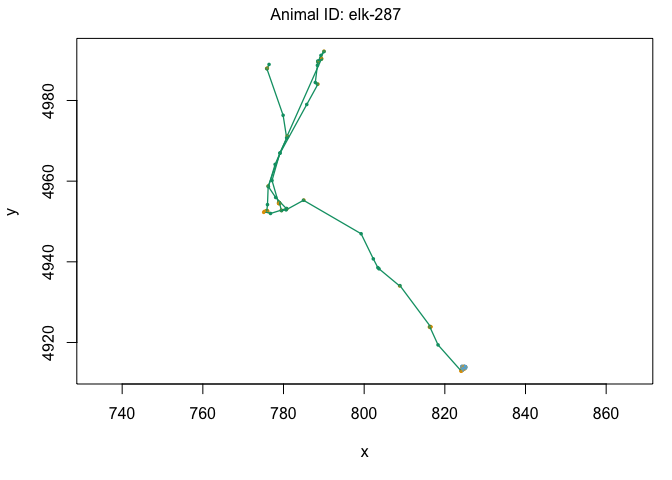
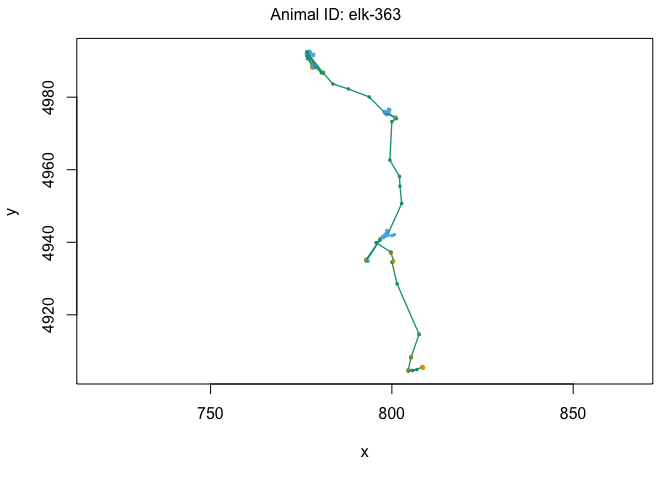
One other cool feature of the moveHMM package is the ability to plot it on satelite data using the moveHMM::plotSat command. In order to do this, we need the coordinates to be in LatLong rather than UTM. Remember, we’ll also need to multiply our UTM coordinates by 1000 to make sure the elk are plotted in the right place:
library(rgdal)
## Loading required package: sp
## rgdal: version: 1.2-16, (SVN revision 701)
## Geospatial Data Abstraction Library extensions to R successfully loaded
## Loaded GDAL runtime: GDAL 2.1.3, released 2017/20/01
## Path to GDAL shared files: /Library/Frameworks/R.framework/Versions/3.4/Resources/library/rgdal/gdal
## GDAL binary built with GEOS: FALSE
## Loaded PROJ.4 runtime: Rel. 4.9.3, 15 August 2016, [PJ_VERSION: 493]
## Path to PROJ.4 shared files: /Library/Frameworks/R.framework/Versions/3.4/Resources/library/rgdal/proj
## Linking to sp version: 1.2-5
utmcoord <- SpatialPoints(cbind(data$x*1000, data$y*1000), proj4string=CRS("+proj=utm +zone=17"))
llcoord <- spTransform(utmcoord, CRS("+proj=longlat"))
lldata <- data.frame(ID=data$ID, x=attr(llcoord, "coords")[,1], y=attr(llcoord, "coords")[,2])
#plotSat(lldata, zoom=8)
Now lets try to create our own HMM using empirical zebra data collected by the Getz Lab. We know how important time is when it comes to movement data, so rather than using a spatial covariate, let’s use a temporal one to see if there is any effect on the transition probabilities.
First, we will bring in the data on Zebra AG253:
zeb253 <- read.csv('Zebra_AG253.csv')
As you can see, we have a lot more observations for this zebra than our elk example. For the sake of time, lets reduce this dataset to a smaller, but still substantial, subset of 500 points:
zebra <- zeb253[10001:10500,]
Now we have some cleaning to do. We can see that we have LatLong rather than UTM, so we’ll need to take care of that. We also need to derive our own temporal covariate using the time stamps.
#Project and transform points into UTM
coords <- SpatialPoints(zebra[,c("Longitude", "Latitude")], proj4string = CRS("+proj=longlat + datum=WGS84"))
coords <- spTransform(coords, CRS("+proj=utm +south +zone=33 +ellps=WGS84"))
#Create an object that splits apart the date from the time in our DateTime column
TOD <- strsplit(as.character(zebra$DateTime), " ")
#Make a data frame with only the hour (extracted from the time)
TOD2 <- data.frame(matrix(0,length(TOD),1))
for (i in 1:length(TOD)) {
TOD2[i,1] <- strsplit(TOD[[i]][2], ":")[[1]][1]
}
#Once again, we divide our units by 1000 to convert from meter to kilometers
x <- as.numeric(coords@coords[,1]/1000)
y <- as.numeric(coords@coords[,2]/1000)
ID <- zebra[,c("Unit.ID")]
TimeOfDay <- data.frame(TOD2)
colnames(TimeOfDay) <- c("TimeOfDay")
#Create one data frame with all of the necessary data for the rest of our analyses
all.data <- data.frame("Easting" = x, "Northing" = y, "ID" = ID, "TimeOfDay" = TimeOfDay)
all.data$TimeOfDay <- as.numeric(all.data$TimeOfDay)
Now we have a nice data frame with 500 observations and 4 columns that looks a lot like the elk_data we imported:
head(all.data)
## Easting Northing ID TimeOfDay
## 1 582.2865 7867.945 AG253 21
## 2 582.2869 7867.941 AG253 21
## 3 582.2877 7867.971 AG253 22
## 4 582.2837 7867.970 AG253 22
## 5 582.2852 7867.969 AG253 22
## 6 582.3653 7867.823 AG253 22
From here, we’ll need to prep the data (i.e., calculate step size and turning angle), make some decisions about the model(s) we want to create and define various initial values to parameterize the model(s). Let’s try two alternatives, just like before, one with 2 states and one with 3 states. Note that we are not including a zero-mass parameter here because there are no points with a step distance of 0, and we will get an error for over-parameterizing. In both models, we will use the time of day as a covariate:
dataHMM <- prepData(all.data, type="UTM", coordNames=c("Easting","Northing"))
summary(dataHMM)
## Movement data for 1 animal:
## AG253 -- 500 observations
##
## Covariate(s):
## TimeOfDay
## Min. 25% Median Mean 75% Max.
## 0.00 4.00 11.00 11.04 18.00 23.00
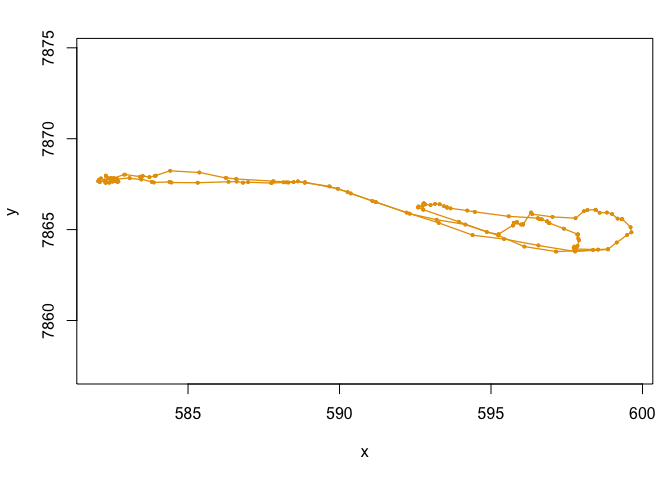
plot(dataHMM,compact=T)
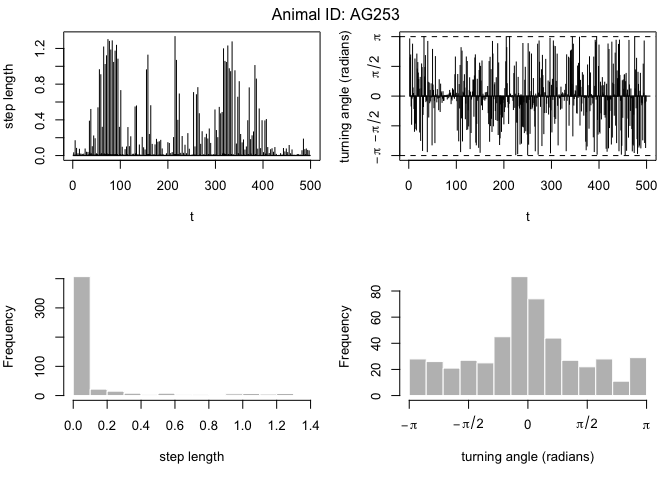
mu0 <- c(0.05, 0.5) # step mean (two parameters: one for each state)
sigma0 <- c(0.05, 0.5) # step SD
#zeromass0 <- c(0.1, 0.05) # step zero-mass
stepPar2 <- c(mu0,sigma0)#,zeromass0)
angleMean0 <- c(pi,0) # angle mean
kappa0 <- c(1,1) # angle concentration
anglePar2 <- c(angleMean0,kappa0)
z <- fitHMM(data=dataHMM, nbStates=2, stepPar0=stepPar2, anglePar0=anglePar2,
formula=~TimeOfDay)
mu0 <- c(0.01,0.1,1) # step mean (three parameters: one for each state)
sigma0 <- c(.005,.05,.5) # step SD
#zeromass0 <- c(0.01,0.05,0.1)
stepPar3 <- c(mu0,sigma0)#,zeromass0)
angleMean0 <- c(0,0,0) # angle mean
kappa0 <- c(0.01,0.5,1) # angle concentration
anglePar3 <- c(angleMean0,kappa0)
z3 <- fitHMM(data=dataHMM, nbStates=3, stepPar0=stepPar3, anglePar0=anglePar3,
formula=~TimeOfDay)
These took a bit longer than the elk example, but now we have two potential HMMs. Before we delve into either one, let’s take a look at the AIC of each to decide which one we want to investigate in more detail:
AIC(z, z3)
## Model AIC
## 1 z3 -993.8181
## 2 z -682.2127
Well now we know that the three-state model performs better, so lets look at that in a bit more detail. We could also decode the states based on this model, but becasue there are so many points in the time series, it will be a little more difficult to see what is happening. Instead, let’s see what kind of proportion of time our zebra spends in each of the behavioral states:
z3
## Value of the maximum log-likelihood: 522.909
##
## Step length parameters:
## ----------------------
## state 1 state 2 state 3
## mean 0.004681104 0.2181646 1.0531548
## sd 0.004748819 0.2076760 0.2062362
##
## Turning angle parameters:
## ------------------------
## state 1 state 2 state 3
## mean -0.05934535 -0.04460118 -0.02913351
## concentration 0.60810439 0.30008983 15.67786990
##
## Regression coeffs for the transition probabilities:
## --------------------------------------------------
## 1 -> 2 1 -> 3 2 -> 1 2 -> 3 3 -> 1 3 -> 2
## intercept -0.8517537 -1.82108118 18.71914 -4.688962 3.602699 -1.808587
## TimeOfDay 0.0138076 -0.02171262 18.94875 -2.587746 18.591922 -1.881991
##
## Initial distribution:
## --------------------
## [1] 1.000000e+00 3.608518e-18 4.236862e-18
plot(z3)
## Decoding states sequence... DONE
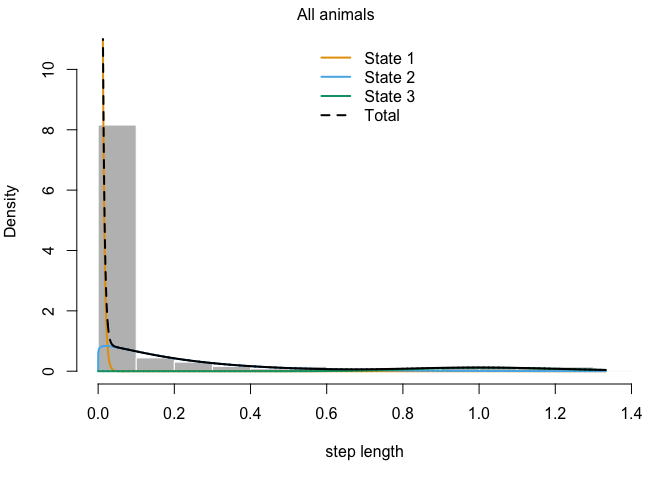
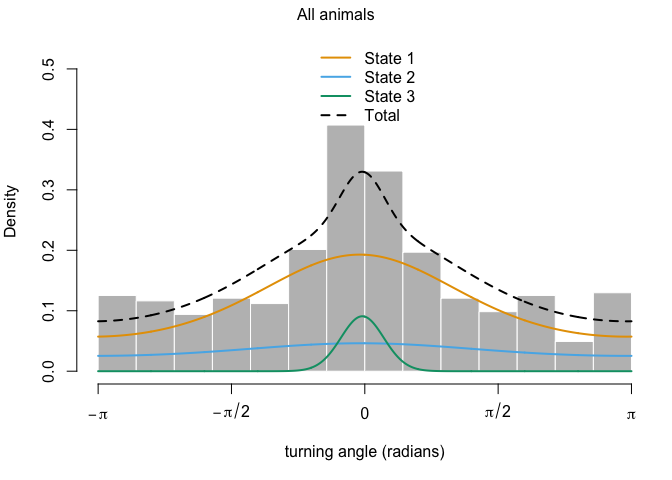
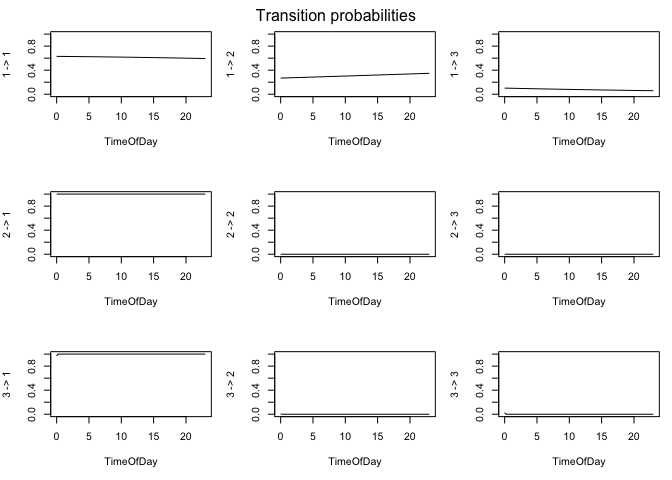
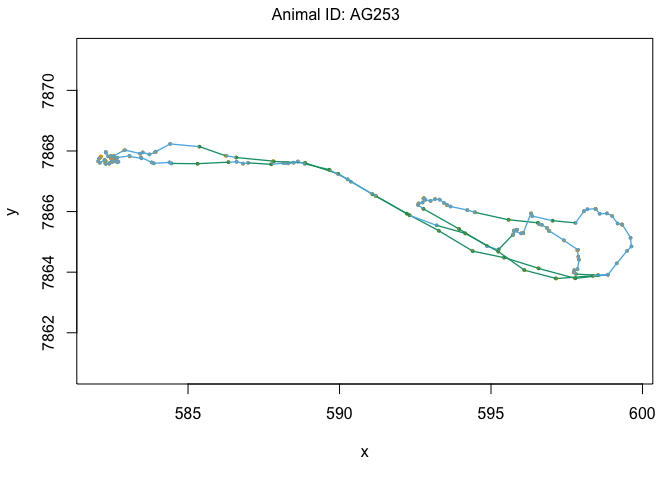
plotStates(z3)
## Decoding states sequence... DONE
## Computing states probabilities... DONE
states <- viterbi(z3)
prop.table(table(states))
## states
## 1 2 3
## 0.722 0.220 0.058
There we have it: over very own temporally-dependent HMM analysis! Based on the output of model z3, try to come up with some potential behaviors that we could associate with each of the three states.
Just for the record, let’s print the output of the 2-state model as well:
z
## Value of the maximum log-likelihood: 354.1064
##
## Step length parameters:
## ----------------------
## state 1 state 2
## mean 0.05560959 0.3327749
## sd 0.10101667 0.5780861
##
## Turning angle parameters:
## ------------------------
## state 1 state 2
## mean -0.09577762 -0.02999288
## concentration 0.25370297 19.65571779
##
## Regression coeffs for the transition probabilities:
## --------------------------------------------------
## 1 -> 2 2 -> 1
## intercept -2.5637680 -1.54368153
## TimeOfDay -0.0335254 0.01620704
##
## Initial distribution:
## --------------------
## [1] 9.999999e-01 1.273311e-07
states.z <- viterbi(z)
prop.table(table(states.z))
## states.z
## 1 2
## 0.812 0.188
Behavioral Change Point Analysis (BCPA)
The next method we’re going to take a look at is the behavioral change point analysis (BCPA), which looks for the points in a time series during which there are notable shifts. In our case, we will be applying the method to a movement trajectory to see where an animal may transition between behavioral states, but technically change point analyses can be performed on any time series data (e.g., fluctuating stock values over time or carbon dioxide concentration in the atmosphere over time). Once we extract some change points, we can actually compare the results to the projected change points based on the HMM to see how closely they align.
Just as with all other packages, bcpa has its own data format that it prefers, so we will use the bcpa::MakeTrack command to translate a set of 100 coordinates (from our 500 point zebra path, for the sake of readability in the outputs) into a usable format:
library(bcpa)
## Loading required package: Rcpp
## Loading required package: plyr
X <- as.numeric(coords@coords[1:100,1])
Y <- as.numeric(coords@coords[1:100,2])
Time <- 1:100
mytrack <- MakeTrack(X,Y,Time)
plot(mytrack)
To obtain the step length and turning angles, use the bcpa::GetVT command, which decomposes the data into single steps and calculates all the statistics:
zebra.VT <- GetVT(mytrack)
head(zebra.VT)
## Z.start Z.end S Phi Theta T.start
## 2 582287+7867941i 582288+7867971i 30.6253432 1.545351 3.0210231 2
## 3 582288+7867971i 582284+7867970i 4.3448065 -2.718833 -4.2641845 3
## 4 582284+7867970i 582285+7867969i 1.7465620 -0.546387 2.1724462 4
## 5 582285+7867969i 582365+7867823i 166.1343854 -1.068061 -0.5216739 5
## 6 582365+7867823i 582361+7867820i 5.6616770 -2.555755 -1.4876938 6
## 7 582361+7867820i 582360+7867820i 0.9657553 -2.660941 -0.1051861 7
## T.end T.mid dT V T.POSIX
## 2 3 2.5 1 30.6253432 2.5
## 3 4 3.5 1 4.3448065 3.5
## 4 5 4.5 1 1.7465620 4.5
## 5 6 5.5 1 166.1343854 5.5
## 6 7 6.5 1 5.6616770 6.5
## 7 8 7.5 1 0.9657553 7.5
The essence of a change point analysis is a sweep across a time series in search of breaks. This sweep can be conducted in a number of ways, but we will focus here on the window sweep, whereby we identify an appropriate windowsize and sensitivity (K) and then the algorithm searches across the time series in search of break points. One can also input a function as the second argument (it can represent any combination of the elements of our zebra.VT dataframe), to serve as a response variable. In this case, we will define a very simple function that account for both the velocity of movement and the direction of movement becasue we dont really have any a priori conception of what exactly causes change points in this path.
zebra.ws <- WindowSweep(zebra.VT, "V*cos(Theta)", windowsize=50, progress=FALSE, K=2)
The object that is returned by this function (which takes a little while to run, hence our reduction of the dataset to a smaller length) is a ws data frame whose final column indicates proposed break points should be and the parameter values associated with before and after those break point.
head(zebra.ws$ws)
## Model LL bic mu1 s1 rho1 mu2
## 1 4 -263.3800 550.3510 2.0004085 32.95492 0.03114557 42.09333
## 2 4 -273.7794 571.1497 4.4003290 33.88606 0.01930639 52.91231
## 3 4 -269.9056 563.4021 3.1709453 33.48897 0.01882455 59.92063
## 4 4 -266.1876 555.9661 3.4200236 34.64970 0.01845554 54.37208
## 5 4 -265.0577 553.7063 -1.5430469 21.66347 0.01914323 32.81839
## 6 4 -273.1228 569.8365 -0.5610108 22.31768 0.02719385 26.81130
## s2 rho2 Break.bb.time
## 1 140.4952 0.03114557 34.5
## 2 154.0854 0.01930639 31.5
## 3 160.1208 0.01882455 34.5
## 4 153.3609 0.01845554 33.5
## 5 190.2381 0.01914323 34.5
## 6 175.0763 0.02719385 31.5
We can take a look at these suggested breakpoints by looking at the smoothed plot (i.e., the summary in which all the windows are averaged to obtain the “smooth” model). In this plot, the vertical lines represent the significant change points, the width of the lines is proportional to the number of time that change point was selected.
plot(zebra.ws, type="smooth")
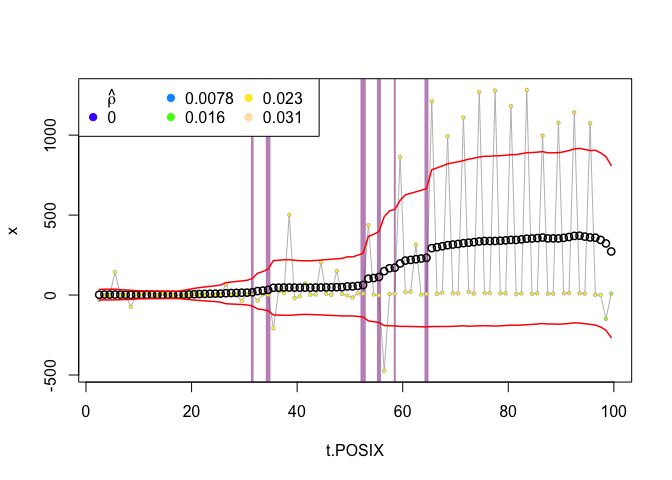
That doesnt offer the clearest picture. We can see that there are about 6 separate change points that have some support. We could, however, add a threshold parameter, which indicates how many of the windows that were swept over the data must have selected a particular changepoint for it to be considered significant. Here, we will use 5 and see what it looks like:
plot(zebra.ws, type="smooth", threshold=5)
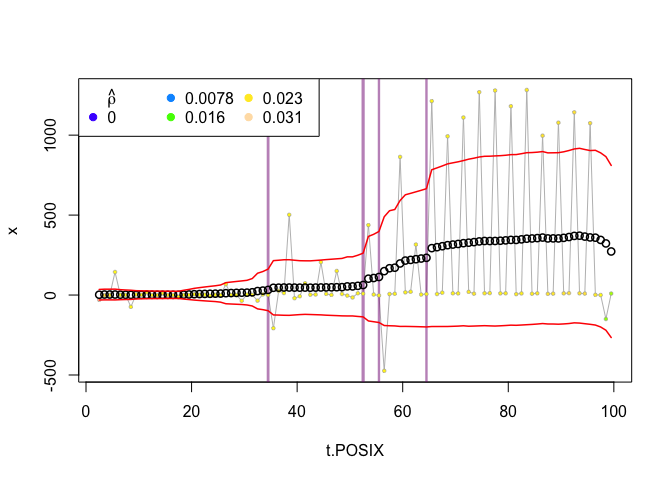
This reduces our number of change points from 6 to 4, and all of them appear to signify reasonable shifts in our response variable (which combines velocity and angle).
An alternative way to search for change points is to use the ‘flat’ rather than ‘smooth’ method. This analysis first selects changepoints that it deems significant by clustering neighboring change points, and then estimates a homogeneous behavior that occurs between those changepoints.
plot(zebra.ws, type="flat")
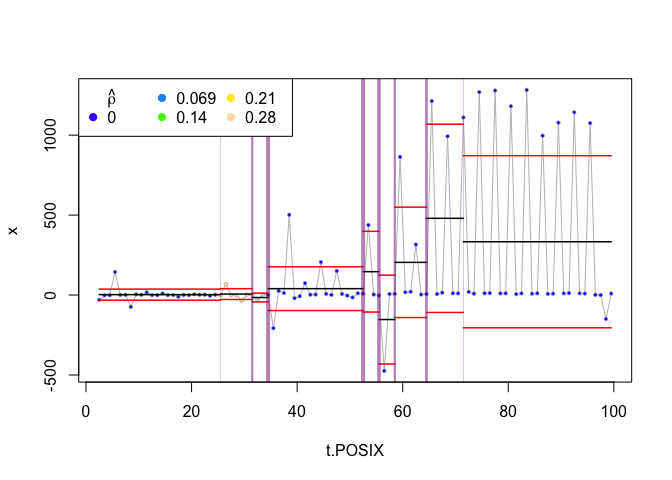
Once again, if we don’t set an equivalent to the threshold parameter (in the case of the ‘flat’ approach, its called clusterwidth), we get quite a few change points. If we set this parameter to 5, we get the following:
plot(zebra.ws, type="flat", clusterwidth=5)
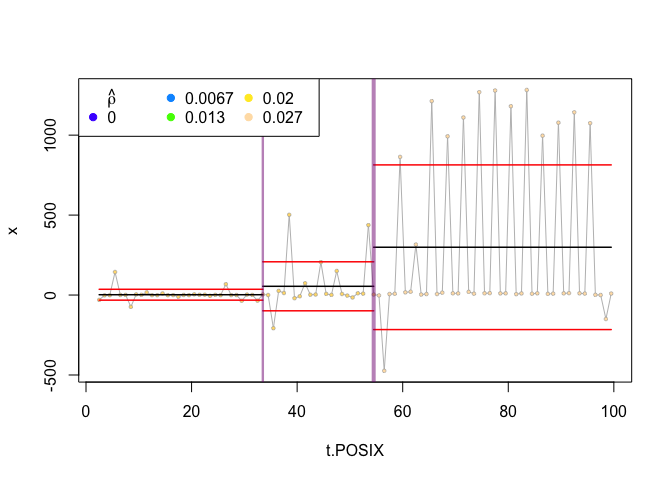
This fairly conservative approach results in only two significant change points in our time series. A visual inspection suggests that these points lead to divisions that appear fairly homogenous within and heterogeneous between segments, so perhaps this is a reasonable set of change points. A summary of these change points can be obtained using the bcpa::ChangePointSummary command:
ChangePointSummary(zebra.ws, clusterwidth=5)
## $breaks
## X1 middle size modelmode middle.POSIX
## 1 1 33.16667 15 4 33
## 2 2 54.82000 25 4 55
##
## $phases
## t.cut mu.hat s.hat rho.hat t0 t1 interval
## 1 (1.5,33.2] 2.002949 34.03233 0.02408837 1.50000 33.16667 31.66667
## 2 (33.2,54.8] 54.651573 153.25818 0.02389902 33.16667 54.82000 21.65333
## 3 (54.8,99.5] 298.955386 514.95409 0.02683257 54.82000 99.50000 44.68000
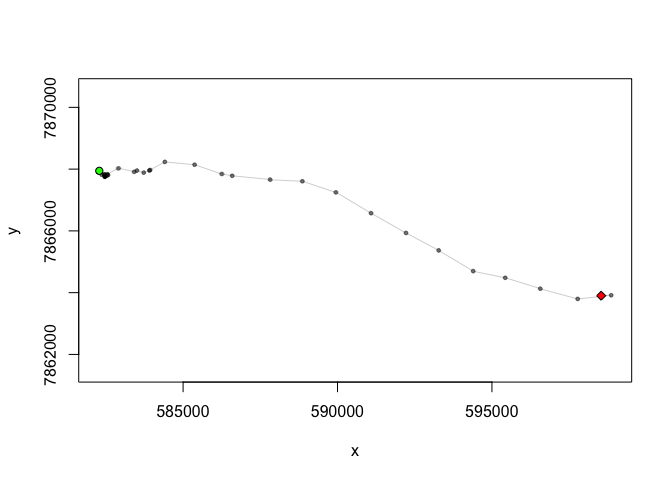
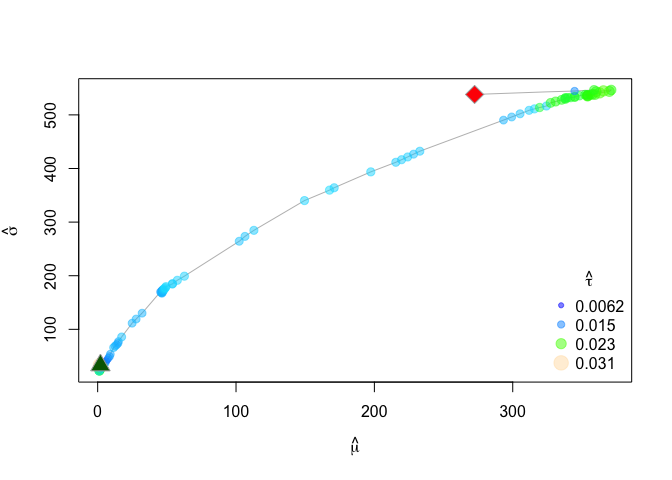
This summmary suggests three phases, with each phase consisting progressively higher velocity (mu.hat). We can also visualize the path itself with the associated change points using the bcpa::PathPlot command or the bcpa::PhasePlot command:
PathPlot(mytrack, zebra.ws, type="flat", clusterwidth = 5, main="Flat BCPA", xlim=c(580000,600000), ylim=c(7862000, 7870000))
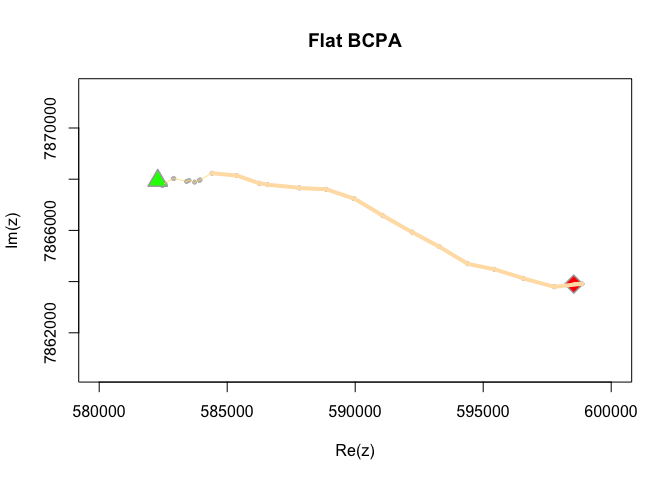
PhasePlot(zebra.ws, clusterwidth = 5)
Now, let’s recall the first 100 values of our HMM predictions from the three-state model and see if they align with these results:
states[1:100]
## [1] 1 2 1 1 2 1 1 2 1 1 2 1 1 2 1 1 1 1 1 1 1 1 1 1 1 2 1 1 2 1 1 2 1 1 2
## [36] 1 1 2 1 1 2 1 1 2 1 1 2 1 1 2 1 1 2 1 1 2 1 1 3 1 1 2 1 1 3 1 1 3 1 1
## [71] 3 1 1 3 1 1 3 1 1 3 1 1 3 1 1 3 1 1 3 1 1 3 1 1 3 1 1 2 1 1
We can see a general pattern, but you can see that the HMM is very sensitive to changes (i.e., it doesn’t have a threshold value associated to determine significant changes). We can, however, see that the there is a pretty notable shift from 2s interspersed with 1s to 3s interspersed with 1s at about t=56. This roughly aligns with the second change point we found with the BCPA method.
Is there anything else that you notice about the dataset based on these outputs?
One important aspect that got lost when we artificially altered the time stamps in the second analysis is the fact that the points were not collected uniformly over time. In fact, state 1 in the HMM actually represents false short steps (for the most part), as these data were collected in a pattern of:
- Point - 10 seconds - Point - 10 seconds - Point - 19 minutes and 40 seconds - Point -
This results in the characteristic peaks and troughs that we see in the BCPA response variable and the pattern of state changes in the HMM. A little data management before beginning these analyses could have prevented this from affecting the results, but this serves as an important lesson in conducting such analyses that we must be careful about the structure of our data, as it will inevitably affect our outputs. It also illustrates some of the ways that we could check throughout the process.